Blog

Engineering
InfluxDB Had Open Storage. Its New Engine Walks Away From It.
InfluxDB 3.11 ships bulk Parquet import and export. But InfluxDB 3 already stored Parquet. The release notes explain why: a new .pt file format.

Engineering
6 Best Time-Series Databases in 2026: An Honest Comparison

Engineering
Elasticsearch Just Admitted What Columnar Databases Have Known for a Decade

Tutorials
Monitor Your Proxmox Cluster with Telegraf, Arc, and Grafana

Tutorials
Migrate InfluxDB to Arc, Straight Off Disk, with tsm2arc

Tutorials
Publish Arc as an Apache Iceberg Table, Zero-Copy
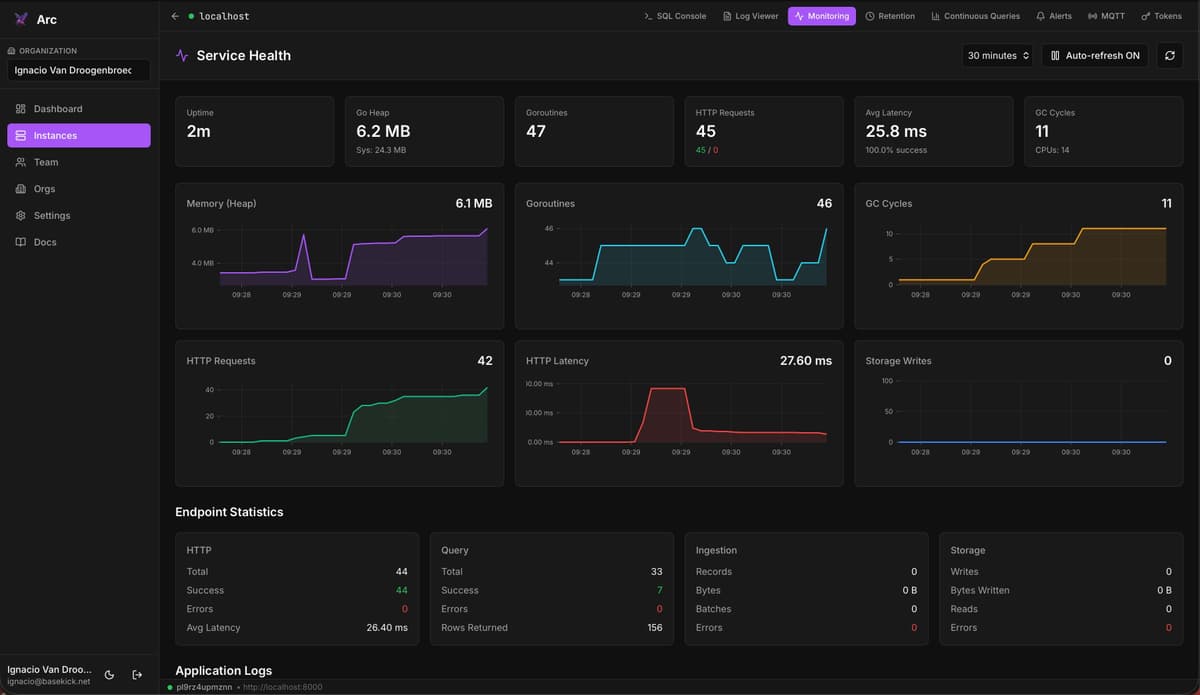
Product
Introducing Arc Launchpad: A Self-Hosted UI for Arc

Engineering
The TCO of 1 Billion Rows: Arc vs InfluxDB 3

Community
What Is a Database? And Why the Right One Changes Everything

Engineering
What Powers America: Seven Years of the Grid, One Live Demo
Engineering
Arc 26.06.3: A Concurrency Fix Worth Shipping Fast, and Homebrew for macOS

Engineering
Anomaly Detection on Sensor Data with Arc, in Pure SQL
Community
What Does a Data Engineer Actually Do? (Explained Simply)
Ready to handle billion-record workloads?
Deploy Arc in minutes. Own your data in open files on your storage. Use for analytics, observability, AI, IoT, or data warehousing.