Arc Tactical Edge Reference Architecture for MOSA Programs

This post describes the reference architecture for deploying Arc across a two-tier tactical edge environment. It is forward-looking. The on-platform ingest capability exists today. The edge-to-rear synchronization that connects the two tiers, Arc Edge Sync, ships in September 2026 as part of Arc 26.09.1.
The intended reader is a program manager or systems integrator evaluating Arc as the data layer for a MOSA-aligned defense or aerospace program. This is not a product pitch. It is a deployment blueprint with enough specificity to answer the question: what does this actually look like when it runs?
The problem this architecture is designed to solve
Defense platforms have a data problem that is structural, not operational. It is not that programs lack sensors. It is not that programs lack compute. The problem is that the data layer sitting between the sensor and the decision was not designed for how tactical platforms actually operate.
Most analytical databases assume persistent network connectivity. Most cloud observability platforms assume a SaaS endpoint is reachable. Most defense data historians assume a fixed installation with a long procurement cycle and a per-tag licensing model that makes sense when you have fifty sensors and breaks when you have fifty thousand.
None of those assumptions hold at the tactical edge.
A vehicle in a contested electromagnetic environment does not have reliable connectivity to a rear data center. A ship over the horizon does not have low-latency access to a cloud warehouse. A forward operating base on a thin SATCOM link cannot stream telemetry in real time to a central historian. And a program running inside a prime contractor's accredited boundary cannot inherit a SaaS dependency that was never part of the ATO.
The result is predictable: platforms collect more data than any force in history and convert less of it into decisions than the mission requires. Telemetry sits in local logs that no system can query. Analysts wait for the platform to return before post-mission review can start. Cross-platform correlation, the kind that would surface a pattern across a fleet, never happens because the data never converges in a form anyone can query.
The reference architecture in this post is designed to close that gap. Two tiers. One database. One data format. One query language. Edge to rear.
What MOSA requires from a data layer
The Modular Open Systems Approach is now statutory policy under 10 U.S.C. § 4401. The intent is straightforward: defense programs must use open standards, avoid vendor lock-in, and enable technology refresh on commercial cycles without re-architecting the system.
Most conversations about MOSA focus on hardware: OpenVPX backplanes, OCP openEDGE blades, standardized module interfaces. Mercury Systems, Curtiss-Wright, and others have moved fast on this. A program can now spec a MIL-STD-810-rated edge server with a commercial Xeon processor and a GPU accelerator, source it from competing vendors, and refresh the compute independently of the mission software.
The software conversation is catching up. A data layer that satisfies MOSA requirements needs to meet several conditions simultaneously.
It must run on any standard Linux on any OCP-compliant or OpenVPX-compatible hardware, without depending on a specific vendor's runtime or SDK. It must store data in an open, non-proprietary format that any analytical tool can read, not in a closed historian format that creates the same lock-in MOSA was designed to escape. It must operate without external network dependencies, because the tactical edge cannot guarantee them. And it must be auditable: open source or otherwise verifiable, with a supply chain posture that survives the scrutiny of a program office or prime contractor security review.
Arc's architectural posture maps directly to these requirements. Single Go binary, no external runtime dependencies. Data stored as Apache Parquet, readable by any analytical tool. AGPL-3.0 source with a commercial license for programs that require it. No phone-home telemetry, no required SaaS calls, no license server check-in. Runs in fully air-gapped environments without modification.
The data format point deserves emphasis. Parquet is not just a storage efficiency choice. It is the technical answer to vendor lock-in. If Arc disappeared tomorrow, every Parquet file it produced would still be readable by DuckDB, Pandas, Polars, Spark, ClickHouse, or any other analytical engine. The archive is not held hostage by the vendor. That is what MOSA requires, and it is what most defense data historians cannot offer.
The two-tier architecture
The reference architecture organizes Arc deployments into two tiers with distinct roles, connected by Edge Sync.
Tier 1: the platform node. Arc runs on the platform itself: on the vehicle, the aircraft, the ship, the FOB server, the rugged edge chassis. It ingests telemetry locally, stores it as compressed Parquet on local NVMe or attached storage, and serves queries autonomously. The platform node has no required connection to anything. It operates through DIL connectivity as the steady state, not as an exception.
Tier 2: the rear node. Arc runs in a rear data center, a sovereign cloud instance, or a command-level aggregation server. Platform nodes sync their Parquet files to the rear node when connectivity is available. The rear node accumulates data from every platform in the fleet and serves cross-platform queries across the full archive.
The diagram below represents the topology. Multiple platform nodes on the left, each running Arc autonomously. Edge Sync moving Parquet files from platform to rear when the link permits. One rear Arc instance on the right, serving the full fleet's data through standard SQL.
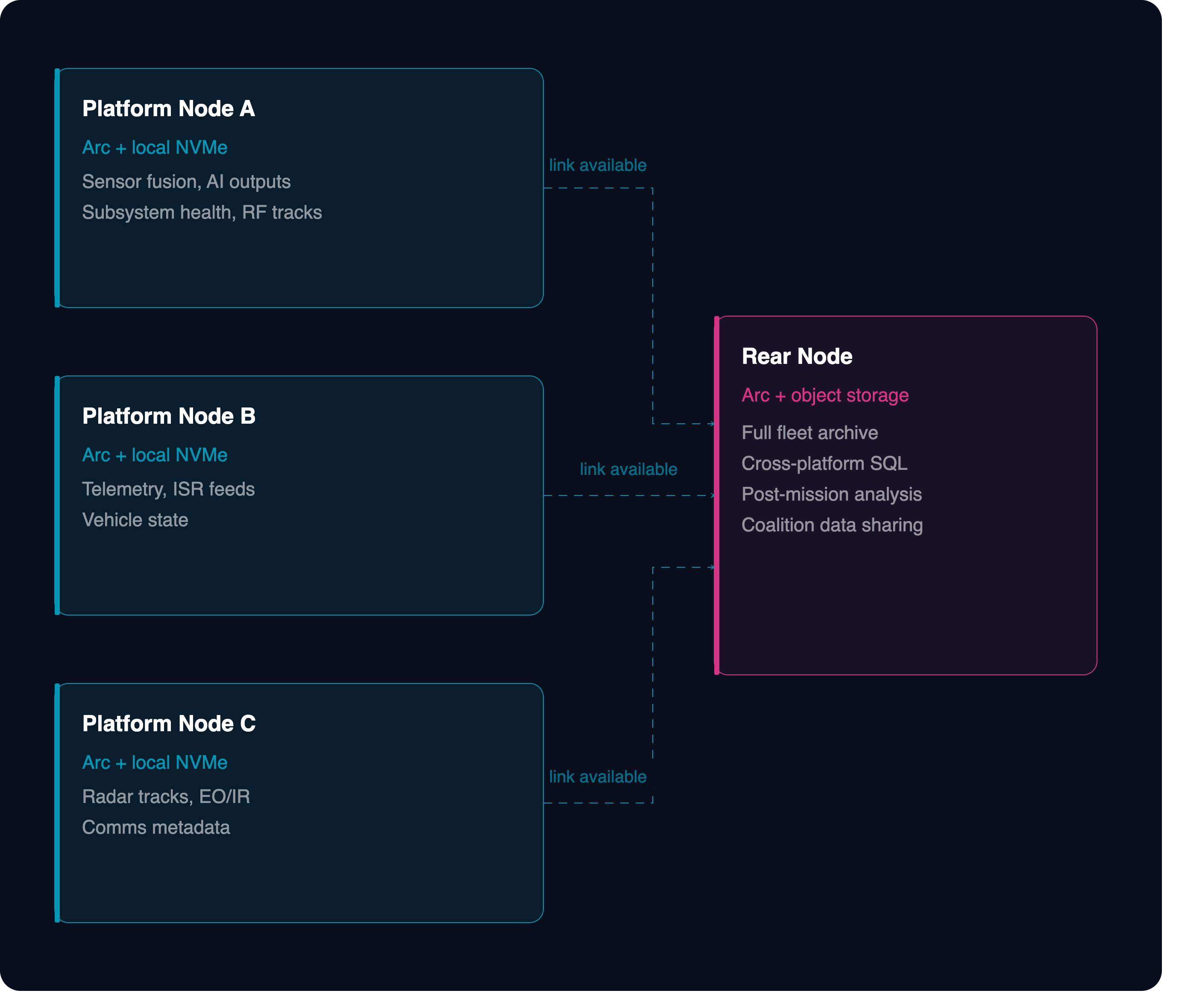
The same database. The same data format. The same query language. The topology changes between tiers; the stack does not.
Tier 1 in detail: the platform node
What runs on the platform
A single Arc binary. No cluster, no sidecar, no Zookeeper, no service mesh. The binary size and runtime footprint are appropriate for the constrained compute environments that rugged edge hardware provides, including OCP openEDGE blades and compact OpenVPX configurations.
The platform node ingests from whatever sources the mission software produces: sensor fusion outputs, AI model inference results, RF spectrum samples, vehicle and subsystem health telemetry, ISR feeds, radar tracks. Arc's ingestion endpoint accepts data over HTTP using a columnar MessagePack protocol, or over the standard InfluxDB Line Protocol for programs that already have Telegraf-based telemetry pipelines. Either path sustains millions of records per second on a single node.
Data lands partitioned by time and stored as ZSTD-compressed Parquet on whatever local storage the platform carries. Typically NVMe. The compaction process merges small write files into larger, denser Parquet files on a configurable schedule, reducing file count and improving query performance without requiring operator intervention.
Local queries run through DuckDB's embedded vectorized engine. An analyst or an onboard inference loop can query data that landed one hundred milliseconds ago with standard SQL. No connectivity required. No round-trip to the rear.
Operating through DIL
The platform node treats disconnected operation as the baseline, not the exception. When the link to the rear is dark, whether because the platform is in a contested EW environment, because it is operating beyond line of sight, or because the satellite window has not opened, Arc continues ingesting and serving local queries without interruption. There is no cluster quorum to lose. There is no SaaS endpoint to fail unreachable.
When Edge Sync ships in September 2026, the platform node will maintain a local ledger of every Parquet file produced since the last successful sync. That ledger persists across reboots. When connectivity returns, the sync agent reads the ledger, contacts the rear node, and begins moving files. The sync is resumable at the file level: if the link drops mid-transfer, the next contact window picks up where the previous one ended. No data is lost and no file is sent twice.
What the platform node does not do
The platform node does not require a connection to operate. It does not require a cluster peer to maintain consistency. It does not buffer in a message queue that can overflow. It does not drop data when a network route is unavailable. It does not need a license server check-in. These are not edge cases that the architecture handles gracefully. They are the design.
Tier 2 in detail: the rear node
What runs in the rear
The same Arc binary. That is the point. There is no separate "server edition" or "cloud variant." The same binary that runs on the platform runs in the rear data center or sovereign cloud instance. The same Parquet files the platform produces are the files the rear ingests. The same SQL queries work on both sides.
The rear node's role is aggregation and analysis. It receives Parquet files from every platform in the fleet via Edge Sync, writes them into a namespaced archive under each platform's identifier, and makes the full fleet's history queryable through a single SQL endpoint. A query that correlates telemetry across twenty aircraft or twelve ground vehicles is a single SQL statement against the rear Arc instance. No ETL pipeline. No format conversion. No separate analytics environment to maintain.
Storage at the rear
The rear node is configured to write to object storage: S3, MinIO, Azure Blob, GCS, or Ceph. The economics of object storage matter here. Arc's ZSTD compression typically reduces raw telemetry to one-fifth to one-seventh of its original size before it ever reaches the object store. Multi-year archives of full-resolution mission telemetry cost what object storage costs, not what a per-tag licensed historian charges. Programs that have been compressing data or shortening retention to control the bill can stop doing that.
The Parquet files in the rear node's archive are not Arc-proprietary. They are standard Apache Parquet, accessible by any tool. A coalition partner who does not run Arc can read the archive with Pandas, Polars, Spark, or any Parquet-compatible engine. There is no proprietary client to license per analyst. There is no format conversion to fund.
Cross-platform analytics
The rear node enables the fleet-level queries that are structurally impossible when each platform's data lives in isolation. Post-mission analysis that previously required data extraction, transport, and reassembly across multiple systems becomes a direct SQL query. Fleet-wide anomaly correlation becomes a window function. Training data assembly for the next mission's AI models becomes a filtered export. After-action reconstruction for compliance or lessons-learned becomes a time-bounded query against the full archive.
Platform identifiers, mission identifiers, sortie IDs, and sensor IDs are stored as ordinary column data in Arc. High-cardinality filtering ("give me all telemetry from platform-07 during mission-23 between 14:00 and 14:45 UTC") does not degrade query performance. That is how columnar storage works, and it is the opposite of how tag-indexed time-series databases behave at fleet scale.
Edge Sync: how the two tiers connect
Edge Sync is the mechanism that moves Parquet files from platform nodes to the rear node when connectivity permits. It ships in Arc 26.09.1 in September 2026. The design is described in detail in the Edge Sync engineering post. The summary relevant to a program manager or SI is this:
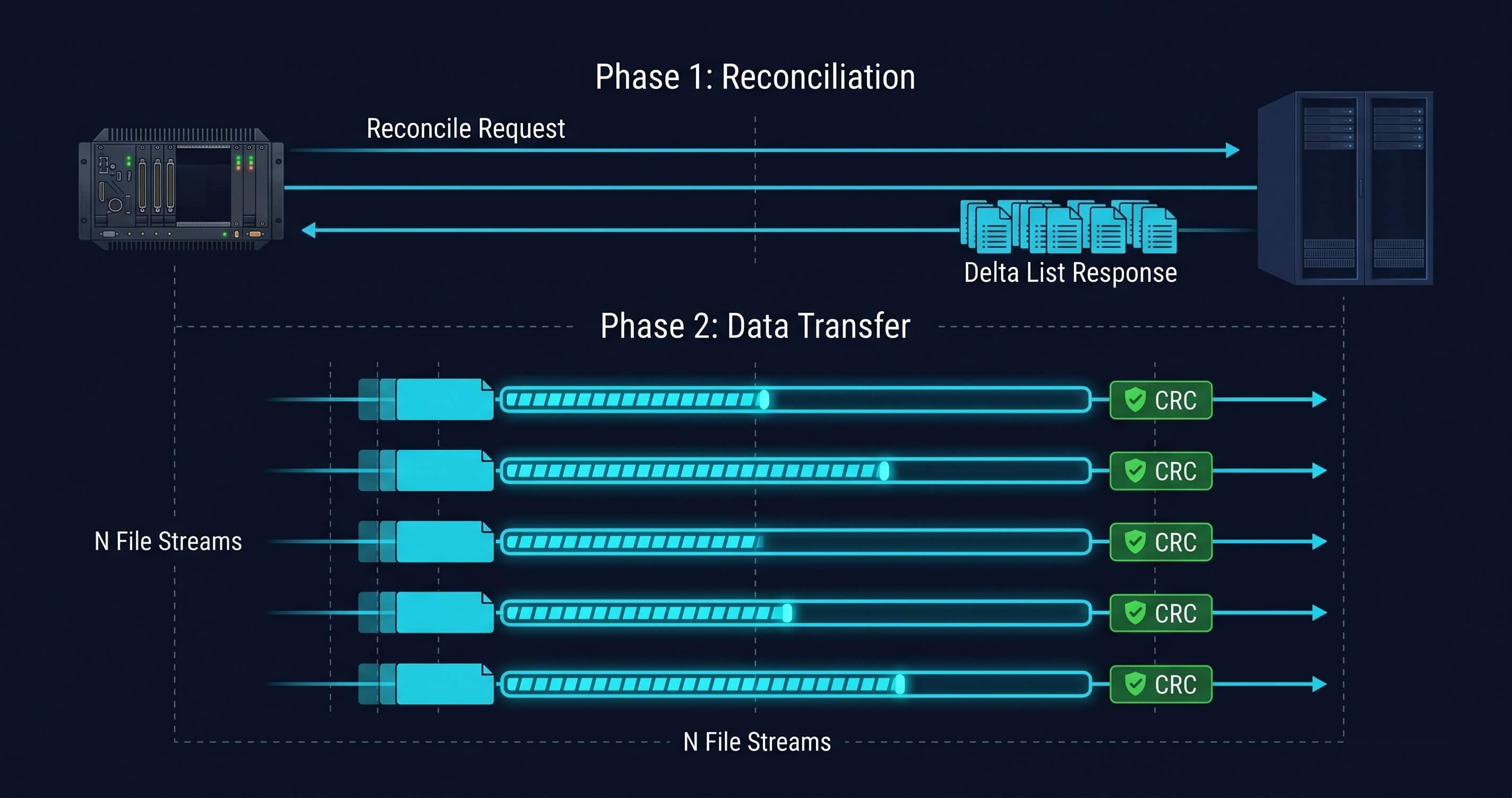
The sync is spoke-initiated. The platform node dials out to the rear. The rear never reaches into the platform. This matters for programs where the platform is behind NAT, a firewall, or an intermittent satellite link. The rear does not need a routable path to the platform.
The sync unit is a file, not a row. Arc already produces immutable, content-addressed Parquet files with per-file SHA256 checksums. Edge Sync moves those files. The rear does not re-ingest row by row. Integrity verification is a consequence of the file format, not an added step.
Discovery is one round-trip, regardless of backlog. After a long dark period, the platform sends a single reconcile request containing the full list of pending files. The rear responds with exactly which files it is missing. Transfer starts immediately, with no sequential probing per file. This matters on a SATCOM link where round-trip latency is measured in hundreds of milliseconds.
Resume is a first-class capability, not a fallback. Every file transfer is individually resumable. When a contact window closes mid-transfer, the next window picks up at the byte offset where the previous transfer ended. For aerospace programs where contact windows are scheduled and bounded, resume is not an edge case. It is the common case.
Delivery is idempotent. If the platform sends the same file twice, whether because an acknowledgment was lost or because the link dropped after the rear received the file but before confirmation returned, the rear ignores the duplicate. No corruption. No gap. The archive converges to the correct state regardless of how many times the link drops.
The licensing split is explicit. The manual sync primitives (the reconcile endpoint, the per-file transfer API, the one-shot CLI to trigger a sync pass) are OSS under AGPL-3.0 and ship in September. The automatic agent, which runs the connectivity-adaptive background loop without operator intervention, is an Arc Enterprise feature and ships in December 2026 as part of Arc 26.12.1. Programs that need the manual primitives can use them from day one without a license key. Programs that need the fleet aggregation story will want the Enterprise agent.
Supply chain and compliance posture
Defense and aerospace programs operate under procurement and security requirements that most commercial software vendors have not designed for. Arc's current posture and roadmap are documented on the defense solutions page. The summary:
Arc is AGPL-3.0 open source. The full source is auditable. A commercial license is available for programs that require it. There are no external runtime dependencies. There is no phone-home telemetry. The binary runs in fully air-gapped, classified environments without modification.
Coordinated vulnerability disclosure is in place and has been exercised publicly. An arc-fips build variant provides FIPS-approved validated cryptography, available starting in release 26.06.2 (July 2026). SLSA Level 2 signed builds with provenance attestation, SBOM publication with every release, and NIST SSDF self-attestation are on the roadmap. CMMC Level 2 and other program-specific compliance certifications are pursued in partnership with the customer when a contract requires them.
For programs running inside a prime contractor's accredited boundary, Arc's posture is compatible: no required external services, deterministic builds, open format storage, self-contained binary, no inherited SaaS risk.
What this architecture does not cover
Two things outside the scope of this post are worth naming explicitly so they do not become false expectations.
Network policy and contact window scheduling are the program's. Edge Sync respects the operator's bandwidth caps, sync schedule, and link selection: satellite, LTE, or physical media. It does not invent a network policy. The program's communications architecture determines when the link is up and what it can carry. Edge Sync moves data within those constraints as efficiently as the two-phase reconcile-and-stream protocol allows.
This is not a streaming architecture. Arc is a columnar analytical database. Edge Sync moves immutable files between Arc instances. It is not a message queue, and it is not a low-latency stream processor. For programs that need durable message streaming between the platform and the rear, Liftbridge, the Basekick Labs streaming layer, is the right tool. The two serve different parts of the stack and are designed to coexist.
Getting started
Arc 26.09.1 ships in September 2026. The manual Edge Sync primitives ship with it under the OSS license. Any program can clone the binary, configure a platform node and a rear node, and run a manual reconcile-and-stream pass between them without a license key.
The automatic Edge Sync agent, the fleet aggregation story, ships in December 2026 as an Arc Enterprise feature.
Three ways to move forward before September:
Evaluate Arc on your data today. Arc is available now as a single binary. Point your existing telemetry pipeline at a local instance and see what the ingestion and query performance looks like on your workload. The download page has Docker, Helm, and .deb options. Most teams have data flowing within an hour.
Run a private technical discovery. For programs with ITAR, sovereign cloud, air-gapped, or classified requirements, we run a private call to scope deployment architecture, integration with your MOSA-aligned hardware stack, supply chain documentation, and licensing. No pitch. Technical questions, honest answers.
Read the Edge Sync design post. The engineering post covers the two-phase protocol, the exactly-once delivery guarantee, the licensing split, and the phasing in detail. If you are evaluating Arc as a data layer for a DIL program, that post has the specifics.
basekick.netDownload ArcArc is available now as a single binary. Point your telemetry pipeline at a local instance and see the ingestion and query performance on your workload. Docker, Helm, and .deb options.https://basekick.net/download basekick.netRead the Edge Sync designThe engineering post covers the two-phase protocol, the exactly-once delivery guarantee, the licensing split, and the phasing in detail.https://basekick.net/blog/arc-edge-sync-dil-tactical-edgeArc is open source under AGPL-3.0. Commercial licensing is available for programs that require it. Source and issue tracker on https://github.com/Basekick-Labs/arc.