Designing Arc Edge Sync: DIL-tolerant telemetry at the tactical edge

Arc ships features quarterly and fixes monthly. The next feature release, Arc 26.09.1, lands in September 2026, and it adds a primitive the tactical edge has been asking for: Edge Sync. Move telemetry off a disconnected, bandwidth-constrained edge node and into a central Arc instance, autonomously, idempotently, and resumably.
This post is the design behind that feature. The architecture is locked, the implementation is starting now, and the licensing model is set. We are publishing the design because the edge deployment audience (defense platforms, industrial IoT, agricultural telemetry, naval systems, forward operating bases, air-gapped factories) deserves to see the reasoning, not just a marketing line, before the code lands.
What the tactical edge actually needs from a data layer
The hardware story for defense edge compute is moving fast. Mercury, Curtiss-Wright, and others are shipping OCP openEDGE blades and OpenVPX modules with Xeon CPUs, NVIDIA accelerators, and NVMe storage inside MIL-STD-810 chassis. The Department of Defense's Modular Open Systems Approach is now policy. Programs can finally mix and match hardware modules across vendors and refresh compute on commercial cycles.
The software story is lagging. Every modular open compute box on a platform generates and consumes data: sensor fusion outputs, AI inference results, RF spectrum samples, vehicle and subsystem telemetry, ISR feeds. Most of that data either ships back under bandwidth pressure, sits in local logs nobody queries, or lands in a closed historian that contractually outlives the program that bought it.
The field deployments differ from the data center in one decisive way: connectivity is the exception, not the rule. A vehicle in a contested EW environment. A ship over the horizon. A FOB on a thin satellite link. A factory cell that is air-gapped by policy. The transport between edge and rear has to treat "disconnected" as the steady state and "connected" as the event.
Most analytical and time-series systems were not built for this. Cluster databases lose quorum and stop accepting writes. Cloud-native observability stacks need outbound connectivity to a SaaS endpoint. Message queues fill local buffers and start dropping. Most of this works fine in a lab and fails the first time it goes to sea.
Arc already runs autonomously at the edge as a single Go binary with local storage. It can ingest at sustained millions of records per second on rugged hardware, store it as compressed Parquet, and serve queries locally with no external dependency. What it has been missing, until 26.09.1, is a first-class way to get that data out to a central instance when the link is available.
What Arc Edge Sync is
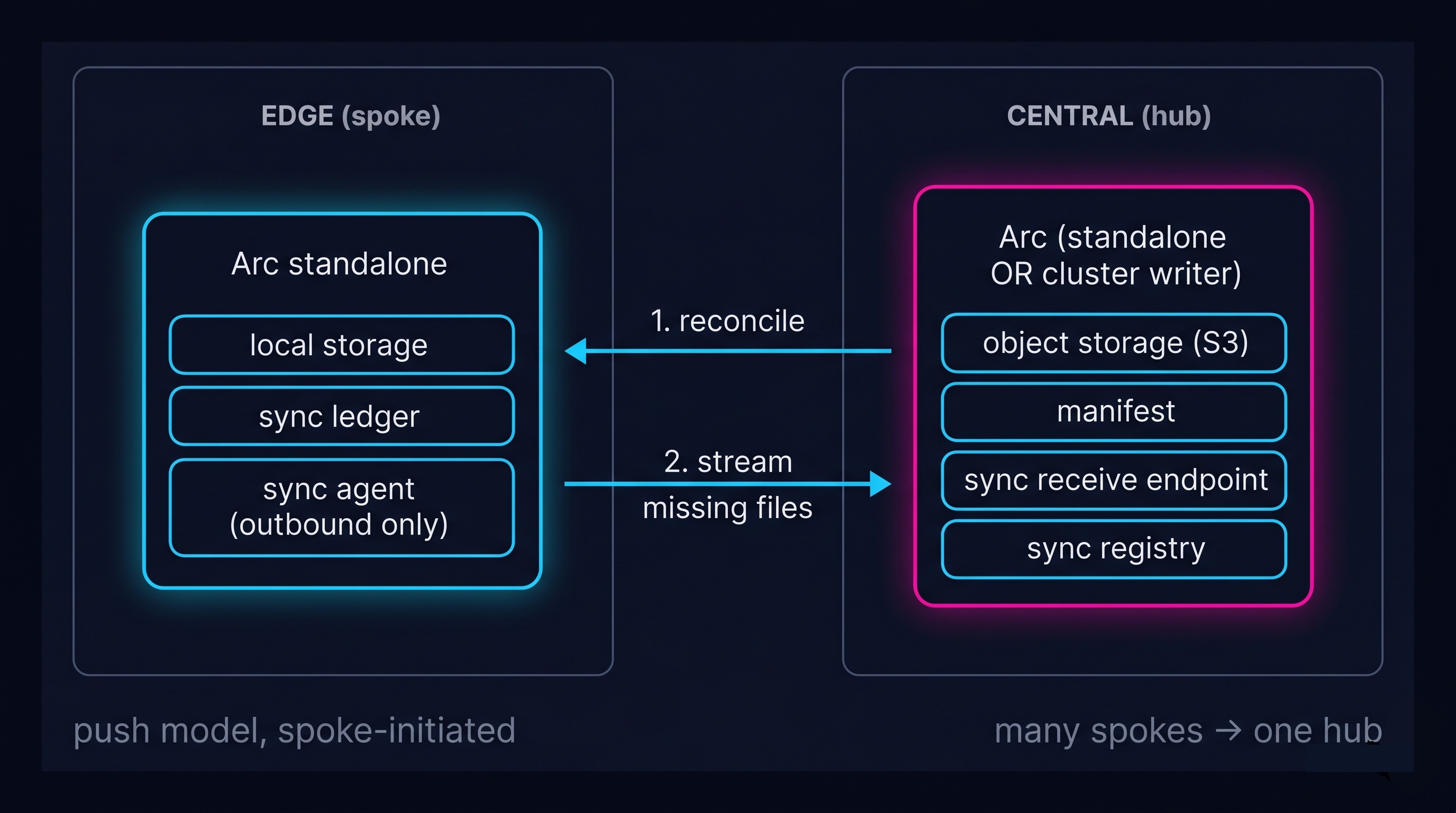
Edge Sync is Arc's spoke-to-hub data transport. A few characteristics, stated plainly:
- Ships files, not rows. Arc already produces immutable, content-addressed Parquet files with per-file SHA256. The sync unit is the file. End-to-end integrity is free, the hub does not re-ingest rows, and idempotency falls out of the design.
- Spoke-initiated push. Edges are behind NAT, intermittent links, or in environments that cannot accept inbound connections. The edge dials out to the hub. The hub never reaches back.
- At-least-once delivery, idempotent receive, exactly-once effect. The wire may deliver the same file twice. The hub converges to the same state regardless.
- Two phases with opposite round-trip economics. Discovery is one batched round-trip. Transfer is N thin per-file streams, each independently resumable.
- One transport interface, multiple transports. HTTPS push in the first release, with S3-relay and sneakernet bundles planned next.
- The edge stays tiny. One SQLite table, one background ticker, one outbound client. No Raft, no cluster, no second process.
The architecture is in the diagram below. Many spokes converge on one hub. The hub is just another Arc, with a receive endpoint enabled.
The two-phase pattern: reconcile, then stream
This is the architectural decision that matters most. It is also the one that took two independent design passes to agree on.
The wrong way to do edge sync over a satellite link is to probe each pending file with its own HEAD request. After a long dark period with 5,000 files in the queue, that is 5,000 sequential round-trips before a single byte of payload moves. The contact window closes before the sync starts. This is the case the aerospace target makes most visible, but it bites every DIL deployment.
The other wrong way is to bundle everything into a multipart/mixed batch. That gets the data moving in one stream, but resume becomes a nightmare. Resuming "part 17 of 240" inside a multipart payload means re-sending framing and replaying state the hub cannot cleanly recover.
Edge Sync splits the problem in half.
Phase 1: Discovery via batched reconcile
The spoke's local ledger holds every file that is pending or in_flight. Instead of probing each one, it sends the whole set in a single request:
POST /api/v1/sync/reconcile
Headers: X-Arc-Spoke-ID, X-Arc-Sync-HubID, + HMAC auth
Body (zstd-compressed): [{path, sha256, size}, ...]
200 OK:
{
"missing": ["metrics/cpu/.../a.parquet", ...],
"present": ["metrics/cpu/.../b.parquet", ...],
"conflicts": [{"path": "...", "their_sha": "..."}]
}
One round-trip discovers the entire delta, regardless of backlog size. After a long disconnect with 5,000 pending files, this is one request, not 5,000.
The present list lets the spoke advance acks for files whose previous confirmation was lost: the lost-ack recovery path, batched. The conflicts list surfaces a same-path-different-content situation proactively, at reconcile time, not lazily when the file finally streams. A different SHA at the same path is either corruption or a spoke-id collision; both are loud alarms, not silent overwrites.
The hub answers all three lists from its own manifest. O(N) lookups, no I/O on the Parquet bytes.
Phase 2: Transfer via per-file resumable streaming
For each file in the missing list, the spoke opens its own HTTP request:
POST /api/v1/sync/file
Headers: X-Arc-Spoke-ID, X-Arc-Sync-Path, X-Arc-Sync-SHA256,
X-Arc-Sync-Size, [X-Arc-Sync-Offset], + HMAC auth
Body: raw Parquet bytes
200 OK → committed (or AlreadyPresent — idempotent no-op)
206 / resume → partial; client continues from returned offset
409 Conflict → same path, different SHA — refuse to overwrite
422 → checksum mismatch on arrival — discard, client retries
429 + Retry-After → hub overloaded, back off
On the hub side: stream the body to a temp path, SHA256 the bytes as they arrive, verify against the declared sum, and only then atomically rename into the final namespaced path and register in the manifest. Verify before commit. A checksum mismatch never lands corrupt bytes in storage.
Each file is its own request. Resuming "part 3 of 24" after a link drop is the same code path as any normal request, just with an X-Arc-Sync-Offset header set to the byte position the spoke got to. For aerospace, where a contact window will close mid-transfer, resume is not an edge case. It is the common case.
The economics, stated plainly: discovery cost is O(1) round-trips. Transfer cost is O(missing files) round-trips, but each is independently resumable and only sends bytes the hub actually lacks. Worst case after a long outage: one reconcile plus only the genuinely-missing streams. Best case (nothing new since last sync): one reconcile, zero streams.
Exactly-once effect, three layers deep
A reliable sync over an unreliable network means accepting that the wire will deliver the same thing twice. The hub has to converge to the same state regardless. Edge Sync handles this with three layered mechanisms.
Content-addressed identity. A file's identity is its namespaced path plus its SHA256. The receive endpoint enforces three cases. Path absent: write, verify, register. Path present with the same SHA256: no-op, return AlreadyPresent. This is the duplicate-delivery and lost-ack case, and it is harmless. Path present with a different SHA256: return 409, do not overwrite. That last case is the one that matters. A differing checksum at the same namespaced path means corruption or a spoke-id collision, and both are alarms.
Ack-then-advance, never advance-then-send. The spoke marks a file synced only after a 2xx or AlreadyPresent response. A dropped link leaves the row in_flight. On restart, in_flight reverts to pending, the next reconcile re-includes it, and because receive is idempotent, re-sending a file the hub already has is a no-op. The cost of a lost ack is one extra entry in the next reconcile batch, never a duplicate and never a gap.
Spoke namespacing. Two platforms will independently generate Parquet files at the same logical path. The hub rewrites incoming paths under a spoke namespace before writing:
hub path = {spoke_id}/{spoke's original path}
= "platform-04/metrics/cpu/2026/06/14/...parquet"
The spoke_id is bound into the HMAC signature, so a spoke cannot write into another spoke's namespace. The namespacing happens entirely on the hub side; the spoke sends native paths and stays dumb. The same spoke can sync to multiple hubs without modification.
Built for disconnected operations. Aerospace is the hardest case
Edge Sync serves any edge that goes dark. The same agent handles a satellite pass, a ship pulling into port, a tractor returning to WiFi range, or a FOB reconnecting after a comms blackout. Different profiles, same code path.
Aerospace is the motivating hardest case: short, scheduled contact windows, integrity-critical telemetry, and a payload too large to guarantee the window stays open. If the design works for a rocket pass, it works for a tractor. The defaults reflect that, but every default is configurable.
The agent loop is connectivity-adaptive, not cron-driven. When the link is dark, the agent costs near nothing. It watches for reachability and tracks the local ledger. When contact is acquired, the agent drains at full configured rate until the window closes. On a platform with persistent LTE (a factory cell, a wind farm), the agent never enters backoff at all. The connectivity gate is the primary control loop.
Ordering is newest-first by default: aerospace and defense platforms want the freshest data first. If the contact window closes mid-backlog, the most recent telemetry already made it. Backfill catches up on the next pass. A factory or agricultural deployment that wants complete history first flips to oldest_first; same agent, different config.
Resume is treated as the common case, not the exception. Offset-resume is a first-class path with end-to-end tests, not a corner case bolted on. A contact window will close mid-file.
Integrity is non-negotiable. Verify-before-commit catches transmission errors. The SHA-bound HMAC catches replay attempts. The 422-on-mismatch retry path also covers flash bit-rot at the edge, which is a real failure mode on hardware exposed to radiation and temperature extremes.
No edge deletion by default. Once a file is synced, the local copy stays on the edge unless an operator explicitly enables post-sync retention. Even then, deletion only happens after a verified, acknowledged round-trip. The edge is the source of truth until the hub confirms.
Licensing: manual is OSS, automatic is Enterprise
A direct answer that defense and aerospace buyers ask early: what's free and what's paid.
OSS (AGPL-3.0): The receive endpoints, the file format, the reconcile and per-file streaming APIs, the air-gap export and import bundles, and the manual one-shot CLI to trigger a reconcile-and-stream pass. A human invokes it. Nothing schedules it. This is sufficient for any team that wants to wire up sync on their own cadence, including classified and air-gapped environments where automation may not be the desired posture.
Arc Enterprise: The automatic agent: the connectivity-adaptive background loop, scheduling, bandwidth policy, multi-hub fan-out, and per-spoke hub-side observability. This is the fleet-aggregation story. Programs that need it pay for it.
The receive side is OSS in both cases. The split sits cleanly between "manual primitives work without a license" and "the background scheduler that turns the primitives into a fleet aggregator requires Enterprise."
Phasing: what ships when
Edge Sync rolls out across the next several quarterly feature releases.
Arc 26.09.1 (September 2026): Manual core. The spoke ledger, reconcile and per-file streaming over HTTPS, the air-gap export and import bundle, per-spoke HMAC, spoke namespacing, 409-on-conflict, the one-shot /sync/run endpoint. OSS. A program can stand up manual edge-to-rear sync the day 26.09.1 lands.
Arc 26.12.1 (December 2026): The automatic agent. Connectivity-adaptive background loop, the FeatureEdgeSyncAuto Enterprise gate, bandwidth caps, 429 backpressure, multi-hub via hub_id. The connectivity-adaptive burst profile becomes the default. Enterprise for the auto-agent; receive endpoints stay OSS.
Arc 27.03.1 and beyond: S3-relay and Azure-relay transports (edge and hub never connect directly; relayed via shared bucket), post-sync edge retention gated on confirmed round-trip, hub-side observability dashboards, hub-as-relay topologies (cell to factory to region) for daisy-chained edges.
The OSS/Enterprise boundary falls cleanly between September and December. The manual primitives ship first, get exercised by real users, and the automatic agent layers on top once the receive path is proven.
What this enables, across deployment types
A few capabilities fall out of this architecture that are hard to get with the alternatives, whether you are running on a MOSA-aligned defense platform, a factory floor, or a remote agricultural sensor grid.
Programs running inside a prime contractor's accredited boundary can use Edge Sync without inheriting a SaaS dependency. No required external services, deterministic builds, open Parquet storage, self-contained binaries. The prime's ATO covers the deployment; the software does not need its own.
Coalition data sharing does not require partners to run Arc. The hub stores everything as Parquet on the program's storage; partners read it with whatever analytical tooling they already use. There is no proprietary client to license per analyst.
Air-gap operations are first-class. The same export/import bundle that produces a sneakernet drop is the same code path the HTTPS transport uses. Move data on a physical drive, verify the HMAC and SHA on arrival, and the hub treats it identically to a network sync.
Multi-platform fan-in with conflict detection. A region-level hub aggregates from every platform under it. Spoke namespacing makes path collisions structurally impossible. A platform identity collision (two boxes accidentally configured with the same spoke_id) surfaces as a 409 conflict the first time it happens, not as silent data corruption months later.
What Edge Sync is and what comes next
Edge Sync v1 is a data transport between Arc instances. It moves already-ingested, already-queryable, already-immutable Parquet files from spoke to hub when the link permits, with the integrity and resumability guarantees described above. It is not a stream processor or a message queue. Different tools, different jobs.
It is also not a replacement for the customer's own networking policy. Bandwidth caps, contact window scheduling, and link selection (LTE vs satellite vs sneakernet) remain operational decisions. Edge Sync respects the policy the operator sets; it does not invent one.
Edge Sync is one piece of a larger bet. Arc at the edge already ingests millions of records per second and serves sub-100ms queries locally with no external dependencies. The long arc (and we mean this literally) is turning the edge Arc instance into a real-time decision layer. Continuous queries running against live telemetry. Onboard anomaly detection triggering alerts before the data ever leaves the platform. AI inference outputs feeding back into the ingest stream and driving autonomous responses. For the aerospace and defense programs asking about this: we are going there. Edge Sync is the first visible step: the data has to move reliably before the decision layer on top of it can be trusted.
If that longer arc matches your program's roadmap, we want to hear about it.
Try it when it lands
Arc itself is open source under AGPL-3.0 at github.com/Basekick-Labs/arc with a commercial license available for programs that need it. When 26.09.1 ships in September 2026, the manual Edge Sync primitives ship with it under the OSS license. You will be able to clone the binary, configure two Arc instances, and run a manual reconcile-and-stream pass between them with no license key.
If you are running Arc at the edge (on a defense platform, a factory floor, a farm, a ship, or a forward operating base) and want to discuss your specific deployment profile, your connectivity pattern, or your certification path, get in touch. We do not pitch on those calls. We listen, ask hard technical questions, and tell you whether Arc is a fit.
basekick.netArc for Defense Tactical EdgeDisconnected, intermittent, and limited-bandwidth operations. Run Arc at the tactical edge and sync to the rear when the link permits.https://basekick.net/solutions/defense-tactical-edge basekick.netArc for Aerospace & DefenseSelf-hosted, ITAR-ready telemetry infrastructure for ground stations, launch vehicles, and satellite constellations.https://basekick.net/solutions/aerospace-and-defense GitHubArc on GitHubOpen source columnar database. AGPL-3.0 licensed. Edge Sync ships in 26.09.1.https://github.com/Basekick-Labs/arc community.basekick.netThe DiveArc community forum. Ask questions, share deployments, and follow the roadmap.https://community.basekick.net