Why Aerospace Companies Are Choosing Arc for Satellite Telemetry

When a satellite passes overhead, a ground station has roughly a 10-minute window to downlink gigabytes of telemetry data. Solar panel voltage, gyroscope readings, thermal sensors, battery health, communications link quality, attitude control — every metric matters. Miss the window and you're waiting 90 minutes for the next orbit. For LEO constellations with hundreds of satellites, this creates a relentless pattern: massive burst ingestion, brief analysis windows, then silence until the next pass.
Traditional time-series databases weren't built for this. They struggle with burst ingestion rates, can't handle the data volume economically over multi-year mission lifetimes, and create vendor lock-in that's unacceptable when your mission timeline is measured in decades.
We've been talking to satellite operators, ground station teams, and launch vehicle companies over the past few months. The pattern is remarkably consistent: they've outgrown their current database, they're frustrated with costs, and they're worried about being locked into a vendor that might not exist when their satellite is still orbiting in 2040.
This post breaks down what makes aerospace telemetry different from typical IoT workloads, why the standard database options don't cut it, and how we built Arc to handle exactly these requirements.
Why Existing Solutions Fall Short
InfluxDB
InfluxDB is the default choice for a lot of teams starting out with telemetry. It works fine at small scale. But aerospace teams consistently hit the same walls:
Cost. InfluxDB Cloud pricing is per-write and per-query. When you're ingesting millions of metrics during every satellite pass, the bill adds up fast. Self-hosted InfluxDB Enterprise requires a commercial license that starts well into six figures for the kind of scale aerospace demands.
Platform maturity. InfluxDB 3.0 moved to Parquet storage, which is a step in the right direction. But the open-source release (Core) is still young — it went GA in April 2025 — and InfluxData's track record of deprecating products (Flux, Kapacitor, InfluxDB 2.x) makes long-term bets risky. For a mission that runs 10-15 years, you need confidence that the platform and its ecosystem will be stable and supported through 2040.
High cardinality. Satellite telemetry is inherently high-cardinality: unique satellite IDs, subsystem identifiers, sensor types, ground station tags. InfluxDB's performance degrades significantly as cardinality grows. With a 200-satellite constellation, each with 5,000 metrics, you're looking at a million unique series — and InfluxDB starts to struggle.
ITAR compliance. ITAR requires that certain telemetry data never leaves US-controlled infrastructure. InfluxDB Cloud doesn't give you that control. The enterprise self-hosted option works, but at a cost that prices out most NewSpace companies.
TimescaleDB
TimescaleDB brings the PostgreSQL ecosystem, which is appealing. But it carries PostgreSQL's baggage:
Operational complexity. Vacuum, autovacuum tuning, partition management, index bloat. Running PostgreSQL at scale for time-series data requires a dedicated DBA. Most satellite operations teams don't have one.
Storage efficiency. PostgreSQL's row-based storage doesn't compress time-series data well. You're looking at 2x compression at best, compared to 3-5x with columnar formats like Parquet. When you're storing years of mission data, that difference is real money. TimescaleDB does support Parquet — but only on their managed Cloud edition. Self-hosted TimescaleDB is still PostgreSQL row storage.
Query performance. Analytical queries — the kind you run for post-pass analysis, anomaly detection, and long-term trend monitoring — hit PostgreSQL's row-oriented engine hard. TimescaleDB adds optimizations, but it's still fundamentally a row store trying to do columnar work.
Generic Solutions (Prometheus, Graphite)
These are monitoring tools, not databases. They work great for ops dashboards showing the last 24 hours. But they weren't designed for long-term retention, complex analytical queries, or the kind of compliance requirements that aerospace demands. No native S3 support, limited query capabilities, and retention policies that assume old data is disposable.
What Aerospace Workloads Actually Look Like
Aerospace telemetry isn't just "IoT but bigger." The workload patterns are fundamentally different from typical sensor monitoring.
Ground Station Operations
A typical commercial ground station network handles 200+ satellite contacts per day. Each contact is a 5-15 minute window where the satellite dumps everything it's collected since the last pass.
During a contact, you're looking at burst ingestion rates of 5-10 million metrics. Then the satellite passes out of range and ingestion drops to near zero until the next contact. This burst-then-idle pattern is the opposite of what most time-series databases are optimized for — they expect steady, predictable write loads.
Data types are mixed: numeric telemetry (voltages, temperatures, pressures), state change events (mode transitions, command acknowledgments), and text logs (onboard computer messages). You need all of it, and you need it queryable.
Retention requirements are non-negotiable: 5+ years of mission data, sometimes the full mission lifetime. Regulatory compliance (ITAR, NOAA licensing, FCC requirements) mandates keeping the data accessible and auditable.
Launch Vehicle Monitoring
Launch telemetry is the most intense burst workload in aerospace. From T-10 minutes through T+600 seconds (engine cutoff), you're ingesting 100K+ metrics per second: engine chamber pressures, turbopump speeds, guidance system outputs, structural loads, thermal readings, propellant levels.
The data volume during a single launch is relatively small (a few GB). But the requirements around it are extreme: zero data loss, real-time streaming to mission control, and the ability to query the entire flight timeline in seconds during post-flight analysis. Compliance requirements include full audit trails and data sovereignty — the flight data can't leave controlled infrastructure.
Satellite Constellation Management
Modern constellations range from 50 to 500+ satellites. Each satellite reports 1,000-10,000 metrics per contact. At scale, you're looking at fleet-wide analytics: which satellites have degrading battery performance? Are there orbital patterns that correlate with thermal anomalies? When does a satellite need to be deorbited based on its telemetry trends?
This requires cross-satellite queries spanning months or years of data. You need to aggregate, compare, and detect anomalies across the entire fleet — the kind of analytical workload that row-oriented databases handle poorly.
The Technical Requirements
When you add it all up, aerospace teams need:
- Ingestion: 5-10M+ metrics/sec during satellite passes (burst)
- Storage: Petabytes over mission lifetime (years of data, multiple satellites)
- Queries: Sub-10 seconds for 1+ year of data per satellite
- Compliance: ITAR, data sovereignty, full audit trails
- Cost: S3-class economics for long-term storage (under $10K/TB/year)
- Portability: Data format that outlives the vendor
How Arc Solves This
Built for Burst Workloads
Arc's architecture handles the burst-then-idle pattern of satellite passes naturally. During a contact window, data flows through configurable flush workers that buffer and batch writes efficiently. Parquet files get written with Snappy or Zstd compression, reducing storage footprint by 3-5x compared to row-based formats.
Between passes, Arc's compaction engine runs automatically — merging small Parquet files from burst windows into optimized, larger files. This means your storage stays clean without manual intervention, and query performance improves over time as data gets consolidated.
Arc supports S3-compatible object storage as a first-class backend. MinIO, Ceph, AWS S3, R2 — any S3-compatible endpoint works. For aerospace, this means you can store years of mission telemetry at object storage economics. We're talking $0.023/GB/month for S3 Standard, or even less with infrequent access tiers. Compare that to block storage at $0.10/GB/month, and the math is clear for multi-year missions.
With Arc Enterprise, tiered storage takes this further: hot data on fast local storage for real-time queries, cold data automatically migrated to S3 Glacier or Azure Archive. Same queries, same SQL — Arc handles the routing transparently.
ITAR-Compliant Self-Hosted
Arc is a single Go binary. No PostgreSQL cluster to manage, no Java runtime, no complex dependency chain. Deploy it on your ITAR-compliant infrastructure — whether that's a government cloud VPC, an on-premises server room, or a containerized environment behind an air gap.
Native TLS secures all communications. Self-hosted S3 via MinIO or Ceph keeps data on your hardware. With Arc Enterprise, RBAC with LDAP/SAML/OIDC integration lets you control exactly who accesses what data. Structured audit logging records every operation for compliance reviews.
Your data stays in standard Parquet files on infrastructure you control. There's nothing phoning home, no cloud dependency, no license server that needs internet access.
Analytics-Ready from Day One
Arc uses DuckDB as its query engine — one of the fastest analytical SQL engines available. This means:
- Columnar execution optimized for aggregations, the bread and butter of telemetry analysis
- Native Parquet reads with no data movement or transformation
- Full SQL support including window functions, CTEs, and joins
- Arrow IPC responses for zero-copy integration with Python, pandas, and Polars
When you need to query a year of satellite telemetry, Arc's time-based partitioning skips every Parquet file outside your time range. It never scans data it doesn't need. The result is sub-second response times on queries that would take minutes in a row-oriented database.
-- Cross-constellation battery health analysis
SELECT
satellite_id,
date_trunc('day', time) as day,
AVG(battery_voltage) as avg_voltage,
MIN(battery_voltage) as min_voltage,
COUNT(*) as readings
FROM telemetry
WHERE time > NOW() - INTERVAL '90 days'
AND metric_type = 'battery_voltage'
GROUP BY satellite_id, day
ORDER BY min_voltage ASCThis kind of query — scanning 90 days of data across an entire constellation — returns in seconds. Try that on InfluxDB with a million series.
No Vendor Lock-In
This is the one that resonates most with program managers planning multi-decade missions.
Arc stores everything in Apache Parquet — an open, industry-standard columnar format. Your data is readable by DuckDB, Spark, Snowflake, pandas, Polars, and dozens of other tools. If Arc disappears tomorrow, your data doesn't go with it.
For a 10-year satellite mission, this isn't a nice-to-have — it's a requirement. You can't bet your mission archive on a platform from a company that might pivot, deprecate products, or shut down. Parquet files are the safe bet. They'll be readable in 2040.
Architecture Patterns
Pattern 1: Ground Station Deployment
The simplest deployment — a single ground station feeding Arc.
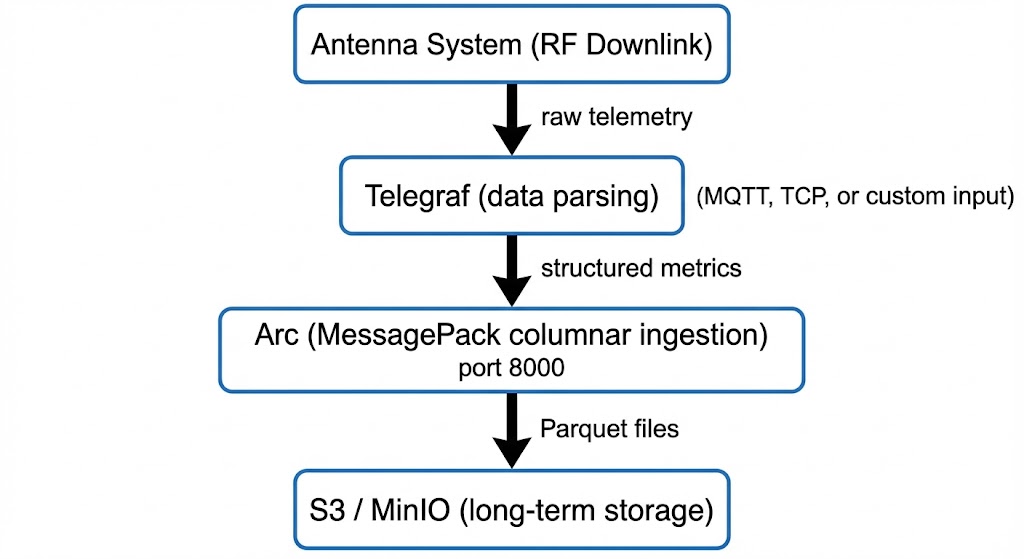
Telegraf handles the protocol translation — whatever format your ground station software outputs (CCSDS, custom binary, MQTT, TCP syslog), there's likely a Telegraf plugin for it. Arc ingests the structured metrics via its MessagePack columnar protocol at maximum throughput.
Pattern 2: Multi-Site Constellation Operations
Multiple ground stations feeding a centralized Arc deployment.
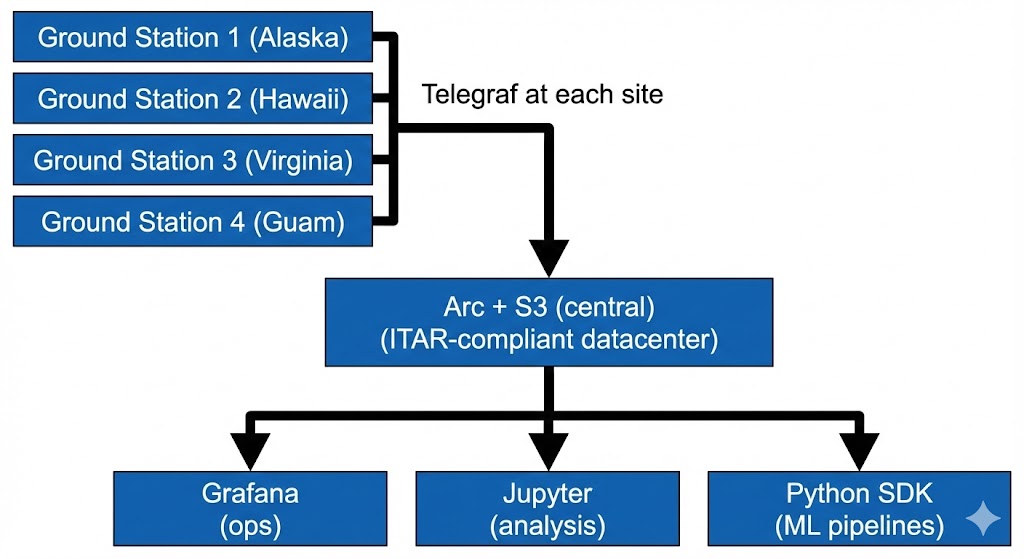
Each ground station runs a local Telegraf instance that forwards metrics to the central Arc deployment. Grafana provides real-time operational dashboards. Data scientists connect via Jupyter notebooks or the Python SDK for deeper analysis. All within your ITAR boundary.
Pattern 3: Hybrid Cloud (ITAR + Analytics)
For teams that need ITAR compliance for raw telemetry but want cloud-scale analytics on derived data.
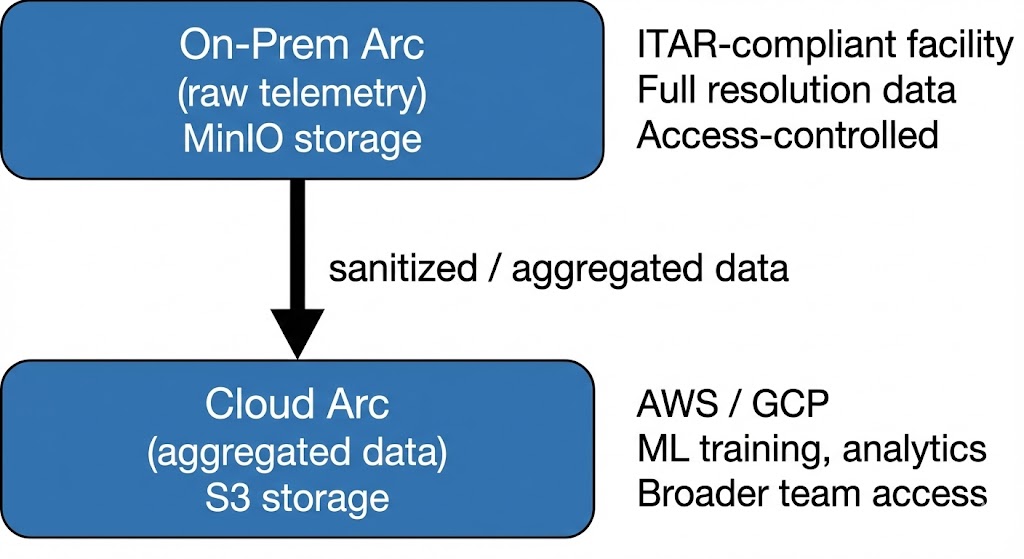
Raw telemetry stays on-premises under ITAR controls. Aggregated or sanitized data flows to a cloud Arc instance where broader teams can run analytics, train ML models, and build dashboards without touching controlled data. Both instances use the same SQL interface, same Parquet format, same tools.
Migration Path
From InfluxDB
This is the most common migration we see. The approach:
- Deploy Arc alongside InfluxDB. Same infrastructure, no risk.
- Configure dual-write in Telegraf. Add an
outputs.arcsection alongside your existing InfluxDB output. Both databases receive the same data. - Validate queries. Run your critical queries against both databases, confirm the results match.
- Switch production traffic. Point dashboards and applications to Arc.
- Migrate historical data. Use Arc's bulk import API to load CSV or Parquet exports from InfluxDB.
- Decommission InfluxDB.
Timeline: 2-4 weeks for a typical deployment. The dual-write phase is the safety net — you're never running without a working database.
From TimescaleDB
- Export data to Parquet using PostgreSQL's COPY command or a direct query export.
- Import to Arc via the bulk import API (CSV or Parquet).
- Update application queries. DuckDB SQL is PostgreSQL-compatible for most analytical patterns. Window functions, CTEs, and standard aggregations work the same way.
- Validate performance against your existing benchmarks.
- Cut over.
Timeline: 1-2 weeks. The main effort is validating any query syntax differences between PostgreSQL and DuckDB SQL.
From Scratch (New Mission)
Starting fresh is the simplest path:
- Deploy Arc — single Docker container or Kubernetes helm chart.
- Configure Telegraf with your ground station input and Arc output.
- Set up Grafana dashboards for real-time operations.
- Start ingesting.
Timeline: 1-3 days from zero to production. Most of that time is configuring Telegraf inputs for your specific ground station software.
Performance Benchmarks
Ingestion
Benchmarked on Apple M3 Max (14 cores, 36GB RAM, 1TB NVMe) with 12 concurrent workers, 1000-record batches. Throughput varies by schema width — narrower aerospace telemetry schemas are faster than wide industrial schemas:
| Data Type | Columns | Throughput | p50 Latency | p99 Latency |
|---|---|---|---|---|
| Aerospace (rocket telemetry) | 3 | 23.8M rec/s | 0.35ms | 2.94ms |
| IoT (sensor data) | 5 | 18.6M rec/s | 0.46ms | 3.68ms |
| Racing (F1/NASCAR) | 9 | 12.8M rec/s | 0.70ms | 4.73ms |
| Energy (wind turbine) | 10 | 11.5M rec/s | 0.81ms | 4.66ms |
| Industrial (pump) | 12 | 9.4M rec/s | 0.99ms | 5.72ms |
23.8 million records per second for aerospace telemetry on a single machine. That's more than enough headroom for any satellite pass burst — or an entire constellation's worth of contacts happening simultaneously.
Compaction
Arc's automatic background compaction merges burst-window Parquet files into optimized larger files:
| Metric | Before | After | Reduction |
|---|---|---|---|
| Files | 43 | 1 | 97.7% |
| Size | 372 MB | 36 MB | 90.4% |
10x storage reduction, faster queries (scan 1 file vs 43), and lower cloud costs.
Queries
Arrow IPC format provides up to 2x throughput vs JSON for large result sets:
| Query | Arrow (ms) | JSON (ms) | Speedup |
|---|---|---|---|
| COUNT(*) Full Table | 6.7 | 9.0 | 1.35x |
| SELECT LIMIT 100K | 55 | 103 | 1.88x |
| SELECT LIMIT 500K | 201 | 420 | 2.10x |
| SELECT LIMIT 1M | 379 | 789 | 2.08x |
| AVG/MIN/MAX Aggregation | 146 | 146 | 1.00x |
| Last 1 hour filter | 12 | 11 | 0.96x |
How Arc Compares
| Metric | Arc | InfluxDB | TimescaleDB |
|---|---|---|---|
| Ingestion (rec/sec, aerospace) | 23.8M | ~1.5M | ~800K |
| Storage cost ($/TB/year, S3) | ~$4.8K | ~$25K (Cloud) | ~$18K (PostgreSQL) |
| Compression ratio | 3-5x (Parquet) | 2-3x | 1.5-2x (PostgreSQL) |
| Vendor lock-in | None (Parquet) | Medium (young ecosystem) | Medium (Parquet only on Cloud) |
| ITAR self-hosted | Native | Enterprise license only | Possible |
For aerospace-specific workloads (burst ingestion with idle periods between satellite passes), Arc's performance advantage is even larger. The buffer and flush architecture is specifically designed for bursty writes, unlike databases that assume steady-state ingestion.
Getting Started
1. Deploy Arc
docker run -d \
--name arc \
-p 8000:8000 \
-e ARC_STORAGE_BACKEND=s3 \
-e ARC_STORAGE_S3_ENDPOINT=s3.amazonaws.com \
-e ARC_STORAGE_S3_BUCKET=satellite-telemetry \
-e ARC_STORAGE_S3_ACCESS_KEY=$AWS_ACCESS_KEY \
-e ARC_STORAGE_S3_SECRET_KEY=$AWS_SECRET_KEY \
-e ARC_STORAGE_S3_REGION=us-east-1 \
-e ARC_STORAGE_S3_USE_SSL=true \
-v arc-data:/app/data \
ghcr.io/basekick-labs/arc:latestFor ITAR deployments, point the S3 endpoint at your MinIO or Ceph cluster instead.
2. Configure Telegraf
# Satellite telemetry input (example: MQTT from ground station)
[[inputs.mqtt_consumer]]
servers = ["tcp://ground-station:1883"]
topics = ["telemetry/#"]
data_format = "json"
tag_keys = ["satellite_id", "subsystem", "sensor_type"]
# Arc output
[[outputs.arc]]
url = "http://arc:8000/api/v1/write/msgpack"
api_key = "$ARC_TOKEN"
database = "satellite_data"
content_encoding = "gzip"3. Query Your Telemetry
SELECT
satellite_id,
AVG(battery_voltage) as avg_voltage,
MIN(solar_panel_current) as min_current,
COUNT(*) as contact_readings
FROM telemetry
WHERE time > NOW() - INTERVAL '7 days'
GROUP BY satellite_id
ORDER BY avg_voltage ASCResources
- Solution overview: Arc for Aerospace & Defense
- Documentation: docs.basekick.net/arc
- Python SDK: pypi.org/project/arc-tsdb-client
- Source code: github.com/Basekick-Labs/arc
Let's Talk
Arc is built for mission-critical workloads where data loss isn't an option and vendor lock-in isn't acceptable.
If you're operating satellites, ground stations, or launch vehicles and need self-hosted infrastructure for ITAR compliance, burst ingestion capacity for satellite passes, years of telemetry storage at S3 economics, and portable Parquet files for multi-decade missions — we'd love to talk.
Arc is open source under AGPL-3.0. Enterprise licenses with clustering, RBAC, tiered storage, and dedicated support are available for production deployments.
Schedule a technical demo: enterprise@basekick.net Join the community: Discord Try it now: github.com/Basekick-Labs/arc