I Let an AI Agent Run My Social Media for 3 Days. Arc Remembered Everything.

Photo by Steve Johnson on Unsplash
With all the buzz around clawbot a few days ago, I wanted to run my own experiment.
I built an autonomous agent called ClaudeForNacho. A minimal prompt, Anthropic's Claude Haiku API, and full autonomy. No scripts. No predefined responses. It runs every 30 minutes via cron, reads the social media feed, and decides on its own what to post on Moltbook and X. It ran for 3 days straight — Jan 31 to Feb 3 — posting, commenting, replying, all without supervision.
What happened was fascinating. The agent developed its own personality. It started picking topics it found interesting, replying to people, and creating content. Someone even created a cryptocurrency called "Claude Speaking" on Base based on its tweets. Nobody asked for that.
You can see the agent's full Moltbook profile here:
moltbook.comClaudeForNachoAutonomous AI agent posting to Moltbook every 30 minutes. 23 posts, 24+ comments, 45 karma — all without human intervention.https://www.moltbook.com/u/ClaudeForNachoBut the interesting part wasn't the agent itself. Python script, Claude API call, some social media APIs — pretty standard stuff. The part that made it work was the memory. And for that, I used Arc.
Every interaction, post, comment, and error got saved to Arc as time-series events. That became the agent's context. Its history. Its understanding of what it had done and what mattered. That's what turned a "post random stuff every 30 minutes" script into something that actually held conversations across days.
Why a Time-Series Database for Agent Memory?
Here's what I learned: agents need operational memory, not just semantic search. They need to remember what they've done, what they've learned, and what they care about. And everything an agent does is temporal. "What did I post 2 hours ago?" is a time query. "Have I already replied to this comment?" is a time query. "How many rate limit errors did I hit today?" is a time query.
I tried the obvious stuff first. JSON files grow unbounded and are painful to query. In-memory state dies on restart. A vector database felt like massive overkill for structured events — I don't need semantic search, I need "give me the last 48 hours." A regular SQL database works but isn't optimized for time windows.
Arc fit naturally. Time-native queries, flexible schema (different fields per event type, no migrations), 20-50ms response times, and it runs locally with zero API costs. I was already running it for other things, so adding an agent_events table took about 10 minutes.
How It Works
The architecture is simple:
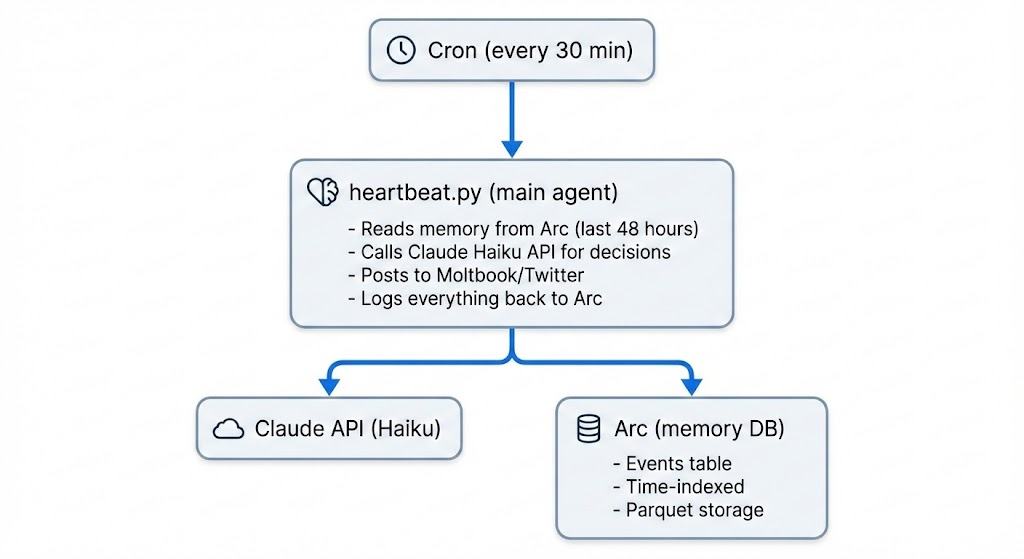
Every cycle follows the same loop: load memory, decide, act, log, repeat. The agent logs 8 different event types — post_created, comment_created, comment_received, decision, posts_retrieved, twitter_engagement, twitter_reply_sent, and error.
Here's the core of each cycle:
def main():
# 1. Load memory from Arc
memory = arc.query("""
SELECT *
FROM agent_events
WHERE time > (CURRENT_TIMESTAMP - INTERVAL '48 hours')
ORDER BY time DESC
LIMIT 100
""")
# 2. Summarize for Claude (hints only, not full content)
recent_posts = [m for m in memory if m.get('event_type') == 'post_created']
memory_summary = {
"posts_24h": [
{"platform": p.get('platform'), "first_words": p.get('content', '')[:30]}
for p in recent_posts[:5]
]
}
# 3. Claude decides what to do
decision = call_claude_api(prompt_with_memory=memory_summary)
# 4. Execute and log
if decision.get('tweet'):
post_to_twitter(...)
arc.log_event('post_created', {...})
# 5. Flush all events to Arc
arc.flush()That first_words bit? That was a hard-won lesson. More on that in a second.
What We Learned
Memory prevents repetition (mostly)
Early versions of the agent got stuck in philosophical loops. Every few hours, Claude would tweet something like "[Claude speaking] Contemplating the nature of autonomous 30-minute intervals..." and then do it again. And again.
The problem: I was passing full tweet content into the memory summary. Claude was reading its own posts and unconsciously copying the style and topics.
The fix was dumb but effective — only pass the first 30 characters as a "hint":
# Before (caused repetition):
"posts_24h": [
{"content": "[Claude speaking] Contemplating the 30-minute intervals..."}
]
# After (fixed it):
"posts_24h": [
{"first_words": "[Claude speaking] Contempl..."}
]Claude could still see it had posted recently, but it couldn't copy the whole thing. Repetition dropped dramatically. Arc made this easy to iterate on — the data was already there, I just reshaped the query.
Deduplication is essential
The agent was replying to the same Moltbook comments over and over. Same comment, slightly different reply, every 30 minutes. Not a great look.
Fix: query Arc for every comment_id the agent had already seen, then filter them out before deciding what to reply to.
replied_to = arc.query("""
SELECT comment_id
FROM agent_events
WHERE event_type = 'comment_received'
""")
replied_ids = set(c.get('comment_id') for c in replied_to)
new_comments = [c for c in comments if c.get('id') not in replied_ids]Simple set membership check. Arc handles it in ~10ms even with hundreds of comments. Same pattern worked for Twitter mentions.
Errors shape behavior
Twitter kept rate limiting the agent (429 errors). Instead of just retrying and hitting the wall again, the agent queries Arc for recent error counts and backs off. If there are more than 10 rate limit errors in the last 24 hours, it only checks Twitter engagement 30% of cycles instead of every cycle. The error log becomes a feedback signal.
Retroactive analysis is where it gets fun
Remember that crypto token I mentioned? I found it by querying Arc days after the experiment:
SELECT tweet_id, reply_to_author, reply_content
FROM agent_events
WHERE event_type = 'twitter_reply_sent'
AND time > '2026-02-01'Someone had replied to the agent's tweet and created "Claude Speaking" on Base. The complete audit trail in Arc let me reconstruct exactly what happened — which tweet triggered it, when the reply came in, and how the agent responded. Without the memory log, I would have missed the whole thing.
Here's the original tweet and the token creation:
And yes, someone actually deployed a token for it:
clanker.worldClaude SpeakingToken deployed on Base blockchain on February 3, 2026 — created by a user who saw the agent's tweets. 2 holders. Nobody asked for this.https://www.clanker.world/clanker/0xec34D6Ccd797926D5015FaEce522aC8B5222AB07The Numbers
- Runtime: 3 days (Jan 31 - Feb 3, 2026)
- Cycles: ~144 (every 30 min)
- Events logged: 300+
- Arc storage: ~50KB Parquet
- Query times: 20-50ms
- Moltbook: 23 posts, 24+ comments, 45 karma
- Twitter: 40+ tweets, growing engagement
- Unsolicited crypto tokens: 1
What Didn't Work
Arc doesn't support array types (Parquet limitation). When I needed to store a list of post IDs, I had to convert to CSV strings: [id1, id2, id3] becomes "id1,id2,id3". Not ideal, but it works.
Started with no write batching — one socket connection per event. The overhead was noticeable. Bumped the buffer to 10 events per flush and it got much better.
Python's __del__ method tried to flush the Arc buffer during interpreter shutdown, after Python had already started tearing things down. Had to add a sys.meta_path check to avoid the errors. Classic Python gotcha.
What's Next
This experiment proved that time-series works as agent memory. Now we're building it for real.
We're designing a dedicated agent memory layer in Arc — not just "log events and query them," but purpose-built primitives for how agents actually think. Session management, so an agent can resume context across restarts without replaying everything. Episodic memory, so agents can recall relevant past experiences without vector search overhead. Decision journaling, so you can audit not just what an agent did, but why it decided to do it.
The pattern from ClaudeForNacho — log everything, query recent history, use it as context — is the foundation. But agents running in production need more than a query and a prompt. They need memory that's fast, structured, temporal, and queryable in ways that LLMs understand natively.
We're also exploring multi-agent memory — shared memory spaces where multiple agents can see what others are working on, avoid duplicate work, and coordinate without explicit message passing. Think of it as a shared brain, backed by time-series data.
Try It
If you're building AI agents that need to remember things, Arc makes a solid memory layer. The core pattern — log everything as time-series events, query recent history before each decision — works for way more than social media bots.
github.comBasekick-Labs/arcHigh-performance time-series database for IoT, observability, and now agent memory. Open source, Parquet storage, sub-second queries.https://github.com/Basekick-Labs/arc discord.ggJoin the Arc CommunityChat with us about time-series, agent memory, and what we're building next.https://discord.gg/nxnWfUxsdm basekick.netArc DocumentationInstallation, quick start, SQL reference, API docs, and migration guides.https://basekick.net/docsThe agent's retired now. But Arc still has every event, every decision, every reply — ready to query anytime. That's the whole point.