Arc 25.11.1: Our First Production-Ready Release
Arc represents three years of development, countless conversations with engineers, and lessons learned from running time-series infrastructure at scale. When we launched the open-source version less than 40 days ago, the response exceeded our expectations.
Today, with 64 instances running in production and development environments, we're ready to release our first stable version: Arc 25.11.1.
Early Adoption
Within 24 hours of release, we've already seen 18 instances of v25.11.1 deployed. Many more are likely running in air-gapped environments or with telemetry disabled—which is perfectly fine with us.
Why Arc Matters
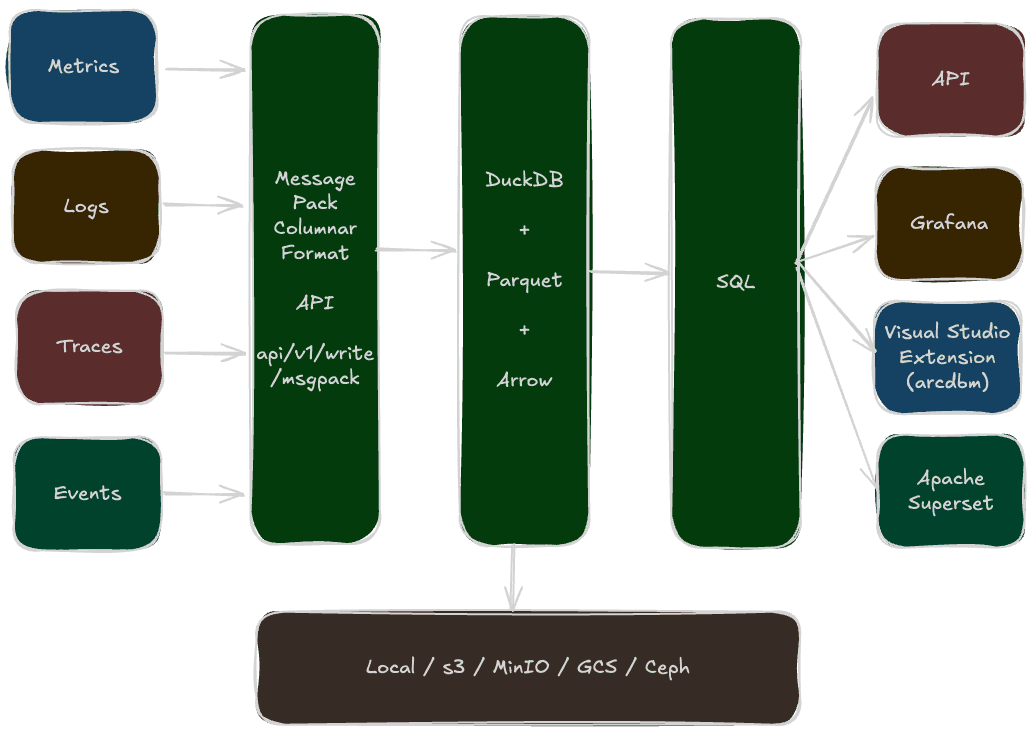
Arc 25.11.1 solves a fundamental problem in observability: data fragmentation.
No more jumping between separate tools for metrics, logs, traces, and events. No more copying timestamps between dashboards. No more context switching when production breaks at 3 AM.
Arc gives you a single source of truth where you can:
- Correlate CPU spikes with application logs in real-time
- Track energy consumption patterns across infrastructure
- Analyze fleet delivery times by season—all in one query
Whether you're debugging production incidents or analyzing long-term trends, Arc eliminates information silos and delivers true unified observability.
Getting Started
Arc 25.11.1 is available as a Docker container and via Helm charts for Kubernetes deployments.
Docker
docker run -d -p 8000:8000 \
-e STORAGE_BACKEND=local \
-v arc-data:/app/data \
ghcr.io/basekick-labs/arc:25.11.1Kubernetes
helm install arc https://github.com/Basekick-Labs/arc/releases/download/v25.11.1/arc-25.11.1.tgz
kubectl port-forward svc/arc 8000:8000Configuration Options
Arc is designed to be flexible. Instead of local storage, you can connect to S3, MinIO, or GCS. Performance tuning is available through environment variables—buffer sizes, flush intervals, and worker counts (defaults to your CPU core count).
Performance Tuning
BUFFER_SIZE=17000 # Buffer size before flush
BUFFER_AGE_SECONDS=5 # Maximum buffer age in secondsQuery Engine Settings
DUCKDB_THREADS=4 # Number of query threads
DUCKDB_MEMORY_LIMIT=8GB # Memory limit for queriesIngesting Data
Arc supports multiple ingestion formats optimized for different use cases.
MessagePack Columnar (Fastest)
Our columnar MessagePack implementation delivers exceptional performance for high-throughput scenarios:
echo '{"m":"cpu","columns":{"time":[1633024800000],"host":["server01"],"usage":[95.0]}}' | \
python3 -c "import sys,msgpack,json; sys.stdout.buffer.write(msgpack.packb(json.load(sys.stdin)))" | \
curl -X POST http://localhost:8000/api/v1/write/msgpack \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/msgpack" \
-H "x-arc-database: default" \
--data-binary @-InfluxDB Line Protocol
For seamless migration from InfluxDB, Arc supports Line Protocol natively:
curl -X POST http://localhost:8000/api/v1/write/line-protocol \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: text/plain" \
-H "x-arc-database: default" \
--data-binary "cpu,host=server01 value=0.64 1633024800000000000"Querying with SQL
Arc uses standard SQL for queries—no proprietary query language to learn:
curl -X POST http://localhost:8000/api/v1/query \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "x-arc-database: default" \
-d '{"sql":"SELECT * FROM cpu WHERE time > NOW() - INTERVAL 1 HOUR","format":"json"}'Integration Ecosystem
Check the scripts folder in our repository for load testing examples and various ingestion patterns. We're actively working on integrations with tools you already use:
- Telegraf: Native Arc output plugin coming soon, enabling direct forwarding of metrics, logs, and traces
- OpenTelemetry: Full OTLP support for traces and logs
- Prometheus: Remote write endpoint for metrics
More integrations are in development based on community feedback.
What's Next
We're excited to see what you'll build with Arc. In the coming weeks, we'll be sharing:
- Real-world use cases and deployment patterns
- Performance optimization guides
- Migration strategies from existing observability stacks
Get Involved
Your feedback shapes Arc's roadmap. Whether it's praise, criticism, or bug reports—we want to hear it all.
Resources:
- GitHub Repository - Star us and explore the code
- Documentation - Complete guides and API reference
- Discord Community - Join discussions and get support
Thank you for being part of Arc's journey. Here's to building better observability infrastructure together.